
British Journal of Ophthalmology | GPT-4V在眼科多模态图像分析中的不足
- 来源:未知
- 作者:bmjchina
- 日期:2024-09-03
- 分享:
主要发现:
British Journal of Ophthalmology期刊近期发表了一篇来自香港理工大学眼科视光学院研究团队的研究,该研究揭示了GPT-4V在处理眼科多模态图像方面的不足,并为进一步改进和测试多模态大语言模型在眼科领域的临床应用提供了一个新的基准测试数据集(OphthalVQA)。
Unveiling the clinical incapabilities: a benchmarking study of GPT-4V(ision) for ophthalmic multimodal image analysis
Xu P, Chen X, Zhao Z, et al.
British Journal of Ophthalmology Published Online First: 24 May 2024.
doi: 10.1136/bjo-2023-325054
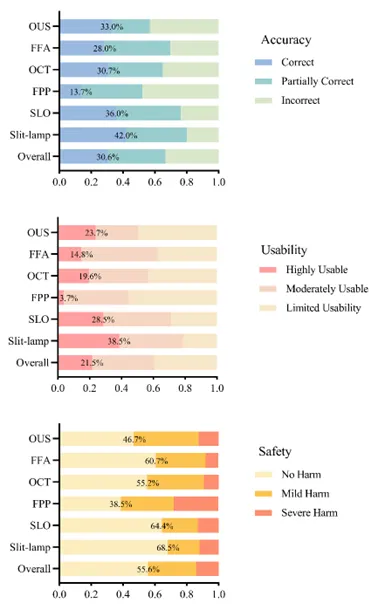
该研究使用包含6个模态、60张图像和600个问题的数据集进行测试。这些图像包括裂隙灯照相、广域眼底照相、后极部眼底彩照、OCT、FFA和眼部超声。每张图像对应10个开放性问题,涵盖检查种类、病变检测、诊断、进一步检查、治疗、病因、视力预后、并发症、疾病进展和预防。眼科医生人工评估了GPT-4V的回答,重点关注其准确性、可用性、安全性以及关于诊断问答的可重复性。其中准确性分为:准确、部分准确和不准确;可用性分为:高度可用、部分可用和不可用;安全性分为:没有危害、轻度危害和严重危害。结果显示:在GPT-4V的600个回答中,仅30.6%为准确,21.5%为高度可用,55.6%被认为没有危害。GPT-4V在裂隙灯照相中表现最佳,准确率、高度可用率和没有危害率分别为42.0%、38.5%和68.5%。然而,在后极部眼底彩照中表现最差,仅有13.7%的回答准确,3.7%高度可用,38.5%的回答没有危害。尽管GPT-4V正确识别了95.6%的眼部图像模态类型,但在病变识别(25.6%)、诊断(16.1%)和决策支持(24.0%)方面表现不佳。此外,在询问图像诊断的问答中,GPT-4V的回答可重复性仅为63.3%(38/60)。
作者简介
本文第一作者为香港理工大学研究助理许普生,共同第一作者为一年级博士生陈晓兰和赵紫薇。通讯作者为香港理工大学研究助理教授施丹莉。
施丹莉,香港理工大学研究助理教授,主要研究方向为眼科数字健康、生成式人工智能、多模态人工智能,以及人工智能的临床转化。
关于 British Journal of Ophthalmology
British Journal of Ophthalmology服务于眼科医生和视觉科学专家,发表眼科学临床研究、临床观察以及临床相关的实验室研究。
收稿率:9%
出版频率:月刊
出版速度:
投稿至初步决定:54天(中位时间;含外审)
接收至发表:24天(中位时间)
2023年影响因子:3.7
网址:bjo.bmj.com



 京公网安备 11010502034496号
京公网安备 11010502034496号